Дополнительная литература
Есть много описаний языков программирования, но немногие из них достаточно точны, чтобы служить полноценным справочным руководством по языку. Авторы данной книги имеют личные причины, чтобы предпочитать книгу "Язык программирования С" Брайана Кернигана и Денниса Ритчи (Brian Kernighan, Dennis Ritchie. The С Programming Language. Prentice Hall, 1988), но она не заменяет стандарт. В книге "С: Справочное руководство" Сэма Харбисона и Гая Стила (Sam Harbison, Guy Steele. C: A Reference Manual. Prentice Hall, 1994), которая дожила уже до четвертого издания, даны хорошие советы по переносимости. Официальные стандарты языков С и C++ доступны в ISO (The International Organization for Standardization). Книга, наиболее близкая к официальному стандарту языка Java, -"Спецификация языка Java" Джеймса Гослинга, Билла Джоя и Гая Стила (James Gosling, Bill Joy and Guy Steele. The Java Language. Specification. Addison-Wesley, 1996).
Книга Ричарда Стивенса "Программирование в системе Unix" (Richard Stevens. Advanced Programming in the Unix Environment. Addison-Wesley, 1992) является отличным пособием для программистов под Unix; в частности, там дан подробный обзор вопросов переносимости между различными Unix-системами.
POSIX (the Portable Operating System Interface) — международный стандарт команд и библиотек, основанный на Unix-системах. Он описывает стандартную среду, переносимость исходного кода, а также унифицированный интерфейс для ввода-вывода, файловых систем и процессов. Этот стандарт описан в нескольких книгах, опубликованных IEEE.
Термин "big-endian" был введен Джонатаном Свифтом в 1726 г.1 Статья Денни Коэна "О святых войнах и мольбе о мире" (Danny Cohen. On holy wars and a plea for peace. IEEE Computer, October 1981) является замечательной басней о порядке байтов, в которой термин "endian" был впервые применен в компьютерной области.
В операционной системе Plan 9, разработанной в Bell Labs, переноносимость является главным приоритетом. Система компилируется из одного и того же исходного кода (без директив условной компиляции!) наЦИ ожестве разных процессоров и повсеместно использует символы icode. Последние версии редактора Sam, впервые описанного в "The Text Editor sam" (Software — Practice and Experience, 17, 11, p. 813-845, 1987), используют Unicode, но тем не менее работают на большом количестве систем. Проблемы работы с 16-битовыми наборами символов вроде Unicode описаны в статье Роба Пайка и Кена Томпсона "Hello, World ? (Документы зимней конференции USENIX'1993. Сан-Диего, 1993. С. 43-50). Впервые кодировка ГР-8 была представлена именно в этой статье. Данный документ, как тоследняя версия редактора Sam, также доступен на Web-сайте, посвященном системе Plan 9 в Bell Labs.
Система Inferno основывается на опыте Plan 9 и в чем-то похожа на j va, поскольку она определяет виртуальную машину, которая может ггь реализована на любой реальной машине, предоставляет язык (Limbo), который может быть скомпилирован в инструкции для этой фтуальной машины, и использует Unicode в качестве основного набор символов. Она также включает виртуальную операционную систему,которая предоставляет переносимый интерфейс ко множеству коммер-;ских систем. Она описана в статье "Операционная система Inferno" Шона Дорварда, Роба Пайка, Дэвида Л. Презотто, Денниса Ритчи, Говарда Трики и Филиппа Винтерботтома (Sean Dorward, Rob Pike, David eo Presotto, Dennis M. Ritchie, Howard W. Trickey и Philip Winter-ottom. The Inferno Operating System. Bell Labs Technical Journal, 2, 1, /inter, 1997).
<
Интернационализация
Если вы живете в Соединенных Штатах, то вы, может быть, забыли, что английский — не единственный язык на свете, ASCII — не единственный набор символов, $ — не единственный символ валюты, что даты могут записываться с указанием сначала дня, а потом уже месяца, что время может записываться в формате с 24-мя часами и т. п. Так вот, еще один аспект переносимости в общем виде связан с созданием программ, переносимых между разными языками и культурными границами. Это на самом деле весьма обширная тема для разговора, и мы будем вынуждены ограничиться освещением лишь нескольких основных концепций.
Интернационализация — этот термин означает создание программ, исполняемых в любой культурной среде. Проблем с этим связано море — от набора символов до интерпретации иконок интерфейса.
Не рассчитывайте на ASCII. В большинстве стран мира наборы символов богаче, чем ASCII. Стандартная функция проверки символов из ctype. h, в общем, успешно справляется с этими различиями:
if (isalpha(c)) ...
Такое выражение не зависит от конкретной кодировки символов, а главное — если программу скомпилировать в локальной среде, то она будет работать корректно и в тех случаях, когда букв больше или меньше, чем от а до г. Правда, имя isalpha ("это буква?") говорит само за себя, а ведь существуют языки, в которых алфавита нет вообще.
В большинстве европейских стран кодировка ASCII, определяющая только значения до 0x7F (7 битов), расширяется дополнительными символами, которые представляют собой буквы национальных языков.
Кодировка Latin-1, широко распространенная в Западной Европе, является расширением ASCII, определяющим значения байтов от 80 до FF я небуквенных символов и акцентированных букв — так, значение Е7 представляет букву д. Английское слово boy представляется в ASCII ли Latin-1) тремя байтами с шестнадцатеричными значениями 62 6F 79, эранцузское слово да гсоп представляется в Latin-1 байтами 67 61 72 Е7 6Е. В других языках определяются, соответственно, другие символы, но они не могут уложиться в 128 значений, не используемых в ASCII, к что существует множество конфликтующих стандартов для символов, привязанных к байтам от 80 до FF.
Некоторым языкам вообще не хватает 8 битов: в большинстве азиат-их языков существуют тысячи символов. В кодировках, используе-,гх в Китае, Японии и Корее, на символ отводится 16 битов. В результа- i возникает глобальная проблема переносимости: как прочитать кумент на некотором языке на компьютере, настроенном на другой ык. Даже если все символы передадутся без ошибок, для прочтения на [ериканском компьютере документа на китайском языке должны как шимум стоять специальные шрифты и соответствующее программное обеспечение. Если же мы захотим на одной машине использовать анг-| [йский, китайский и русский языки, проблем у нас возникнет море.
Набор символов Unicode — попытка улучшить описанную ситуацию, юдоставив единую кодировку для всех языков мира. Unicode совмес-' :ма с 16-битовым подмножеством стандарта ISO 10646; в ней исполь-ется 16 битов на символ. Значения от OOFF и ниже относятся к Latin-1,то есть слово gargon будет представлено 16-битовыми значениями 0067 61 0072 ООЕ7 006F 006Е. Кириллица занимает значения от 0401 до 04FF,а идеографическим языкам отведен большой блок, начинающийся ЮОО. Все известные и некоторые почти неизвестные языки мира пред-авлены в Unicode, так что именно этой кодировкой и стоит пользовать для передачи документов между странами или для хранения текста, .писанного на разных языках. Unicode стала весьма популярна в Интер-;те, и некоторые языки программирования даже поддерживают ее как стандартный формат: например, Java использует Unicode как родной на-ip символов для строк. Операционные системы Plan 9 и Inferno испольч ют Unicode более широко — даже для имен файлов и пользователей, icrosoft Windows поддерживает набор символов Unicode, но не считает о стандартом; большинство приложений Windows до сих пор лучше; .ботает с ASCII, хотя соотношение стремительно меняется в пользу: nicode.
Надо сказать, что и у Unicode есть недостатки: символы в ней уже не гещаются в один байт, поэтому текст в Unicode страдает от проблемы >рядка байтов. Для преодоления этой напасти документы в Unicod перед передачей между программами или по сети обычно преобразуются в кодировку потока байтов, называемую UTF-8. В ней каждый 16-битовый символ кодируется для передачи как последовательность из 1, 2 или 3 байтов. Набор символов ASCII использует значения от 00 до 7F, все они умещаются в один байт при использовании UTF-8. Таким образом, получается, что UTF-8 односторонне совместима с ASCII. Значения между 80 и 7FF представляются двумя байтами, а значения от 800 и выше — тремя.1 В UTF-8 слово gargon представляется байтами 67 61 72 СЗ А7 6F 6Е; значение Unicode E7 — символ g — представляется в UTF-8 двумя байтами — СЗ А7.
Совместимость UTF-8 с ASCII весьма полезн-а, поскольку благодаря ей программы, рассматривающие текст как непрерывный поток байтов, могут работать с текстом Unicode на любом языке. Мы опробовали программу markov из третьей главы с текстом в UTF-8 на русском, греческом, японском и китайском языках, и она работала без каких-либо проблем. Для европейских языков, слова в которых разделяются ASCII-символами пробелов, табуляции или перевода строки, программа выдавала вполне сносный текст. При использовании других языков для того, чтобы получить что-то приемлемое на выходе, пришлось бы изменять правила разбиения текста на слова.
С и C++ поддерживают "широкие символы" (wide characters), которые представляются 16-битовыми или еще большими целыми. Суще-CTByiw и соответствующие функции, которые могут быть использованы для обработки символов в Unicode или в другом расширенном наборе символов. Строковые константы из широких символов записываются как L". . ,". Однако и здесь возникает большая проблема с переносимостью: программа с константами из широких символов может быть воспроизведена только на дисплее, использующем тот же набор символов. Поскольку символы должны быть конвертированы в поток байтов вроде UTF-8 для передачи между машинами, язык С предоставляет функции для преобразования широких символов в байты и обратно. Однако какое преобразование использовать? Интерпретация набора символов и описания кодировки потока байтов таятся в недрах библиотек, и вытащить их оттуда достаточно сложно; ситуация складывается не в нашу пользу. Может статься, в отдаленном светлом будущем все наконец придут к согласию об использовании единого набора символов, но пока что от фоблемы порядка байтов никуда нам не деться.
Не ориентируйтесь только на английский язык. Создатели пользова-гельского интерфейса должны помнить, что в различных языках на вы-зажение одного и того же понятия может потребоваться совершенно эазное количество символов, так что на экране и в массивах должно эыть достаточно места.
Как же быть с сообщениями об ошибках? По крайней мере, в них не должно использоваться жаргона или сленга; лучше всего писать на самом простом языке. Полезно еще собрать тексты всех сообщений в каком-то одном месте программы — тогда можно будет быстро перевести их все.
Существует множество местных культурных особенностей, например формат дат mm/dd/yy используется только в Северной Америке. Если существует вероятность того, что ваша программа будет использоваться в другой стране, от таких особенностей надо по возможности избавиться. Иконки в графическом интерфейсе очень часто зависят от традиций; если понятия, на которых базируется зрительный образ, пользователю незнакомы, такая иконка его только дезориентирует.
<
Изоляция
Нам хотелось бы иметь единый исходный код, который бы компилировался без изменений во всех системах, но, к сожалению, это может быть нереально. Однако было бы ошибкой позволить непереносимому коду расползтись по всей программе, как это и происходит при условной компиляции.
Выносите системные различия в отдельные файлы. Когда для разных систем требуется разный код, его лучше выносить в отдельные файлы — один файл на каждую систему. Например, текстовый редактор Sam работает под Unix, Windows и в ряде других операционных систем. Интерфейсы с системой меняются от среды к среде очень широко, но большая часть кода Sam везде идентична. Все различия, связанные с конкретной системой, вынесены в отдельные файлы: unix. с содержит код интерфейса с системами Unix, a windows, с — со средой Windows. В этих файлах реализуются переносимые интерфейсы с операционной системой, различия же получаются скрытыми. Таким образом, можно сказать, что Sam написан для своей собственной виртуальной операционной системы, которая переносится на различные реальные системы с помощью пары сот строк кода на С, реализующих несколько небольших, но непереносимых операций, вызывающих функции конкретной системы.
Самое интересное, что графические оболочки различных операционных систем не играют почти никакого значения: Sam имеет собственную переносимую библиотеку для своей графики. Несмотря на то что написать такую библиотеку, конечно же, гораздо труднее, чем просто адаптировать код под данную систему (код интерфейса с системой X Window, например, по своим размерам приближается к половине всего остального ко,ш Sam), суммарные затраты для нескольких систем получаются все равно меньше. При этом не надо забывать, что графическая библиотека ценна сама по себе и использовалась для создания и других переносимых программ.
Sam — это довольно старая программа; в наши дни переносимые графические оболочки, такие как OpenGL, Tcl/Tk и Java, доступны для большого числа платформ. Создание кода на их основе вместо использования собственных графических библиотек обеспечит вашим программам большую область применения.
Прячьте системные различия за интерфейсами. Абстрагирование — мощный способ разграничения переносимой и непереносимой частей программы. Хороший тому пример — библиотеки ввода-вывода, имеющиеся в большинстве языков программирования: они оперируют абстрактным представлением внешней памяти в терминах файлов, которые можно открывать, закрывать, читать или записывать, не затрагивая вопросов их физического расположения или структуры. Программы, которые придерживаются этого интерфейса, будут исполняться на любой системе, где он реализован.
Реализация редактора Sam представляет собой пример абстракции другого рода. Интерфейс описан для файловой системы и графических операций, а программа использует только свойства этого интерфейса. Сам интерфейс использует те возможности, которые имеются в конкретной операционной системе, что приводит к появлению абсолютно разных реализаций для разных систем, но программа, использующая его, зависит только от этого интерфейса, а не от его конкретной реализации, и поэтому ее не требуется изменять при переносе между системами.
Подход к переносимости, реализованный в системе Java, — пример того, насколько далеко можно здесь продвинуться. Программа на Java транслируется вЪперации "виртуальной машины", модели компьютера, которую можно реализовать на любой настоящей машине. Библиотеки Java предоставляют унифицированный доступ к возможностям системы: графике, пользовательскому интерфейсу, сети и т. п.; библиотеки же отображают этот доступ в возможности локальной системы. Теоретически должно быть возможно исполнить Java-программу (даже после трансляции) где угодно без каких-либо изменений.
<
Язык
Придерживайтесь стандарта. Первое, что необходимо для создания переносимого кода, — это, конечно, использование языка высокого уровня, причем его стандарта, если таковой определен. Двоичные коды переносятся плохо, исходный код — несколько лучше. Однако и для него трудно, даже для стандартных языков, описать точно, каким именно образом компилятор преобразует его в машинные инструкции. Очень немногие из распространенных языков представлены единственной реализацией: обычно имеется множество производителей различных версий для различных операционных систем, которые к тому же со временем изменяются. Каждая версия будет обрабатывать ваш код по-своему.
Почему стандарт не является строгим описанием? Иногда стандарт неполон и не описывает отдельных специфических случаев. Иногда он намеренно неконкретен: например, тип cha r в С и C++ может иметь знак, а может и не иметь; он даже не обязательно должен быть 8-битовым. Подобные детали оставлены на усмотрение создателя компилятора; в этом есть свои плюсы: стимулируется появление новых эффективных реализаций; снимаются ограничения, накладываемые на железо, но жизнь программиста, конечно, несколько усложняется. Вообще, степень проработанности стандарта зависит от многих глобальных причин. И наконец, нельзя забывать, что языки достаточно запутанны, а компиляторы весьма сложны; в них могут быть неправильности интерпретации и ошибки реализации.
Иногда же языки вообще не стандартизованы. Официальный стандарт ANSI/ISO С был принят в 1988 году, а стандарт ISO C++ ратифицирован только в 1998-м. На момент написания этой книги не все из распространенных компиляторов поддерживают это официальное описание. Язык Java сравнительно молод, и его стандарт можно ждать только через несколько лет. Вообще стандарт языка разрабатывается только после того, как создаются несколько конфликтующих* версий, которые надо унифицировать, а сам язык получает достаточно широкое распространение, оправдывающее затраты на стандартизацию. А между тем по-прежнему надо писать программы и поддерживать в этих программах различные среды исполнения.
несмотря на то что пщ
Итак, несмотря на то что пщ знакомстве со справочными руководствами и стандартами складывается впечатление жесткой спецификации языка, они никогда не описывают язык полностью, и различные версии компиляторов могут создавать работоспособные, но несовместимые друг с другом реализации. Иногда возникают даже ошибки. Вот довольно характерный пример: подобные внешние описания недопустимы в С и C++
? *х[] = {"abc"};
Проверив с десяток компиляторов, мы выяснили, что лишь несколько из них корректно определяют пропущенный определитель типа — слово char для х. Значительная часть выдает предупреждение о несовместимости типов (очевидно, те, что используют старое описание языка: они неверно полагают х массивом указателей на int), а еще пара компилировала этот недопустимый код, не сделав ни вздоха.
Следуйте основному руслу. Неспособность некоторых компиляторов выявить ошибку в приведенном примере весьма прискорбна, но зато мы теперь сможем осветить важный аспект переносимости. У каждого языка есть свои непроработанные моменты, точки зрения на которые разнятся (например, битовые поля в С и C++), и благоразумие подсказывает избегать их использования. Стоит использовать только те возможности, описание которых недвусмысленно и хорошо понятно. Очевидно, что именно такие возможности, скорее всего, будут широко доступны и реализованы везде одинаковым образом. Мы называем их основным руслом (mainstream) языка.
Трудно однозначно определить, какие именно конструкции входят в это основное русло, но зато те, что в него не входят, определить просто. Совершенно новые возможности, такие как complex или комментарии // в С, или возможности, специфичные для конкретной архитектуры, вроде ключевых слов near и far, обязательно создадут вам проблемы. Если что-то в языке настолько необычно или непонятно, что для того, чтобы разобраться, вам приходится консультироваться с "языковым правоведом" — экспертом по чтению его описаний, не используйте такую возможность вовсе.
В своем обсуждении мы сконцентрируем основное внимание на С и C++.
С существует уже более десятка
широко распространенных и универсальных языках. Стандарт С существует уже более десятка лет, и язык очень стабилен, правда, разрабатывается новый стандарт, так что впереди очередные подвижки. А вот стандарт C++ появился совсем недавно, и потому еще не все реализации этого языка приведены с ним в соответствие.
Что можно считать основным руслом в С? Этот термин обычно относят к установившемуся стилю использования языка, но иногда лучше принимать во внимание грядущие изменения. Например, первоначальная версия С не требовала создания прототипов функций. Описание функции sq rt выглядело при этом так:
? double sqrt();
что определяло тип возвращаемого значения, но не параметров. В ANSI С были добавлены прототипы функций, в которых определялось уже все:
do.uble sqrt(double);
Компиляторы ANSI С должны воспринимать и прежний синтаксис, но мы настоятельно рекомендуем вам забыть об этом и всегда писать прототипы для всех функций. Это сделает код более безопасным, вызовы функций будут полностью проверены на совместимость типов, и при изменении интерфейса компилятор это отловит. Если в коде употребляется вызов
func(7, PI);
a func не имеет прототипа, компилятор не сможет проверить корректность такого вызова. Если библиотека впоследствии изменится так, что у func станет три аргумента, компилятор не сможет предупредить о необходимости внесения изменений в программу, потому что старый синтаксис не предусматривает проверки типов аргументов функций.
C++ — более мощный и обширный язык, и стандарт его появился лишь недавно, поэтому говорить об основном русле применительно к нему несколько сложнее. Например, нам представляется очевидным, что STL войдет в это основное русло, что происходит, однако, не мгновенно, и поэтому некоторые существующие реализации языка поддерживают STL не в полной мере.
Избегайте неоднозначных конструкций языка. Как мы уже говорили, некоторые вещи в стандартах умышленно оставлены неопределенными для того, чтобы предоставить создателям компиляторов большую свободу для маневра.Список таких неопределенностей обескураживающе велик.
Размеры типов данных. Размеры основных типов данных в С и C++ не определены. Не существует никаких гарантированных свойств, кроме общих правил, гласящих, что
sizeof(char) <= sizeof (short) <= sizeof(int)
<= sizeof(long) sizeof(float)
<= sizeof(double) %
а также. что char должен иметь как минимум 8 битов, short и int — как минимум 16, a long — по крайней мере 32. Не требуется даже, чтобы значение указателя умещалось в inj.
Проверить, какие значения использует конкретный компилятор, достаточно просто:
Обмен данными
Текстовые данные передаются между системами в неизменном виде, | так что это самый простой и универсальный способ для передачи произ вольной информации между системами.
Для обмена данными используйте текст. С текстом легко оперировать посредством множества программ; его можно обрабатывать разными, самыми неожиданными способами. Например, если вывод одной программы нельзя использовать напрямую для ввода в другую, то скрипт на Awk или Perl позволяет легко его преобразовать в нужный вид. С помощью g rep можно производить отбор строк, а ваш любимый редактор поможет произвести более сложные преобразования. Кроме всего прочего, I текстовые файлы легко документировать, да и пояснений к ним требуется гораздо меньше, потому что их всегда можно прочитать. Комментарий в текстовом файле может указывать, какая версия программы необ- \ ходима для обработки данных: например, первая строка файла PostScript определяет версию языка (и, возможно, тип документа):
%!PS-Adobe-2.0
В противоположность текстовым двоичные файлы требуют для своей j обработки специализированные средства, и их редко удается использовать совместно даже на одной машине. Существует множество известных программ, преобразующих произвольные двоичные данные в текст. Среди них стоит назвать binhex для Macintosh, uuencode и uudecode для Unix и различные инструменты, использующие кодировку MIME для преобразования двоичных данных в почтовые сообщения. В главе 9 мы расскажем о ряде средств паковки и распаковки двоичных данных для их передачи с сохранением переносимости. Кстати, уже само обилие таких инструментов подчеркивает наличие серьезных проблем, связанных с двоичными форматами.
С передачей текста связана одна давняя проблема: PC-системы (операционные системы D'OS и Windows) используют для обозначения конца строки символ возврата каретки '\г' к символ перевода строки ' \п', а системы Unix — только символ перевода строки. Возврат каретки — это артефакт, дошедший до нас от древнего устройства, называемого телетайпом, который имел операцию возврата каретки (CR) для возврата печатающего механизма в начало строки и отдельный оператор протяж-'ки на строку (LF — от Line Feed) для перевода этого механизма на следующую строку.
в современных компьютерах уже нет
Несмотря на то что в современных компьютерах уже нет кареток, которые бы надо было возвращать, программное обеспечение для PC, по большей своей части, продолжает ожидать этой комбинации (известной также как CRLF, произносится "curliff") в конце каждой строки. Если в файле отсутствуют возвраты каретки, то он может быть проинтерпретирован как одна гигантская строка, при этом счетчики строк и символов могут вести себя непредсказуемым образом. Некоторые программы умеют изящно справляться с этой проблемой, но таких - меньшинство. Надо сказать, что PC не единственный виновник подобного безобразия: благодаря последовательному внедрению требований совместимости некоторые современные сетевые стандарты, такие как HTTP, также используют CRLF для разделения строк.
Мы можем посоветовать использовать стандартные интерфейсы, которые воспринимают CRLF в зависимости от конкретной системы -либо (для PC) удаляя символ \г при вводе и добавляя его обратно на выходе, либо (для Unix), никогда даже не создавая его. Для файлов, которые должны будут передаваться туда и обратно, необходимо написать программу, преобразующую их форматы.
Организация программы
Существуют два основных подхода к переносимости, которые мы назовем объединением и пересечением. Объединение подразумевает использование лучших возможностей каждой конкретной системы; компиляция и установка при этом зависят от условий конкретной среды. Результирующий код обрабатывает объединегше всех сценариев, используя преимущества каждой системы. Недостатки этого подхода включают большой размер кода и сложность установки, а также сложность кода, напичканного условными компиляциями.
Используйте только то, что доступно везде. Мы рекомендуем придерживаться другого подхода, пересечения: использовать только конструкции, имеющиеся во всех системах, для которых делается программа. Этот подход также не лишен недостатков. Первый его недостаток состоит в том, что требование универсальной применимости может ограничить либо круг систем, предназначенных для использования, либо перечень приемлемых языковых конструкций. Второй недостаток — в некоторых системах производительность программ может оказаться далекой от совершенства.
Для сравнения двух описанных подходов рассмотрим пару примеров, сделанных по принципу объединения, и обдумаем, как они будут выглядеть для пересечения. Как вы увидите, код, основанный на объединении, уже проектируется как непереносимый, хотя хорошая переносимость и является вроде бы основной его целью, а код пересечения получается не только переносимым, но еще и более простым.
Следующий небольшой фрагмент пытается справиться с системой, в которой по некоторым причинам нет стандартного заголовочного файлa stdlib. h:
Переносимость
Наконец, стандартизация, так же как и соглашения, может служить еще одной демонстрацией строгого порядка. Но, в отличиеЪт соглашений, она принимается в современной архитектуре как продукт, хоть и украшающий нашу технологию, но опасный из-за ее потенциального доминирования и грубости.
Роберт Ветури Сложности и противоречия в архитектуре
Написать корректную и эффективную программу трудно. Поэтому если программа уже работает в одной среде, то вам, скорее всего, не захочется повторять пройденный путь ее создания при переходе на другой компилятор, процессор или операционную систему. В идеале программа не должна требовать внесения никаких изменений.
Этот идеал называется переносимостью (portability). На практике термин "переносимость" нередко относят к более слабому свойству: программу проще видоизменить при переносе в другую среду исполнения, чем написать заново. Чем меньше изменений надо внести, тем выше переносимость программы.
Вы можете спросить, почему вообще зашел разговор о переносимости: если программа будет исполняться в какой-то конкретной среде, зачем тратить время на то, чтобы обеспечивать ей более широкую область применения? Ну, во-первых, каждая хорошая программа почти по определению начинает с какого-то момента применяться в непредсказуемых местах. Создание продукта с функциональностью более общей, чем изначальная спецификация, приведет к тому, что меньше сил придется тратить на поддержку продукта на протяжении его жизненного цикла. Во-вторых, среда исполнения меняется. При замене компилятора, операционной системы, железа меняются многие параметры окружения программы. Чем меньше программа зависит от специальных возможностей, тем меньше вероятность возникновения сбоев при изменении условий и тем проще программа адаптируется к этим условиям. И наконец, последнее и самое важное обстоятельство: переносимая программа всегда лучше написана. Усилия, затраченные на обеспечение переносимоести программы, сказываются на всех ее аспектах; она оказывается лучше спроектированной, аккуратнее написанной и тщательнее протестированной. Технологии программирования переносимых программ непосредственно привязаны к технологиям хорошего программирования вообще.
Естественно, степень переносимости должна определяться исходя из реальных условий. Нет такой вещи, как абсолютно переносимая программа, — разве только программа, опробованная не во всех средах. Однако мы можем сделать переносимость одной из своих главных целей, стараясь создать программу, которая бы выполнялась без изменений практически везде. Даже если эта цель не будет достигнута в полном объеме, время, потраченное на ее достижение, с лихвой окупится, если программу придется переделывать под другие условия.
Мы хотим посоветовать следующее: старайтесь писать программы, которые бы работали при всех комбинациях различных стандартов, интерфейсов и сред, в принципе подходящих для ее исполнения. Не старайтесь исправить каждую ошибку переносимости, добавляя дополнительный код, наоборот, адаптируйте программу для работы при новых ограничениях. Используйте абстракцию и инкапсуляцию, чтобы ограничить и контролировать те непереносимые фрагменты кода, без которых не обойтись. Если ваш код сможет работать при всех ограничениях, а системные различия в нем будут локализованы, он станет еще и более понятным.
<
Переносимость и внесение усовершенствований
Одним из наиболее огорчительных источников проблем переносимо-1 сти является изменение системного программного обеспечения за время жизненного цикла. Изменения могут затронуть любой интерфейс системы, приводя к неоправданной несовместимости версий.
При изменении спецификации изменяйте и имя. Наш любимый (если)
можно так выразиться) пример — изменение свойств команды Unix: echo, которая в изначальном виде предназначалась для простого вывода аргументов:
% echo hello, world
hello, world
%
Однако со временем эта команда стала ключевой частью многих тов оболочки, и перед ней встала необходимость генерировать формате рованный вывод. Теперь echo стала некоторым образом интерпретирс вать аргументы, то есть стала неким аналогом printf:
% echo 'hello\nworld
hello
world
%
Новые возможности, конечно, полезны, но из-за них у всех скриптов, использующих echo в изначальном варианте, возникли проблемы с совместимостью. Поведение
% echo $PATH
стало зависеть от того, какая из версий echo используется. Если переменная случайно содержит обратную косую черту (что вполне может произойти в DOS или Windows), то echo попытается интерпретировать ее. Это похоже на разницу в выводе через printf(str) и printf ("%s", str) в случае, если переменная str содержит знак процента.
Мы привели только часть истории про echo, но уже то, что сказано, иллюстрирует основную проблему: изменения в системе приводят к появлению версий программ с преднамеренно различным поведением, что создает непреднамеренные проблемы с переносимостью. И исправить эти ошибки зачастую оказывается непросто. Проблем было бы гораздо меньше, если бы новая версия echo получила и новое имя.
Приведем еще один пример. В Unix существует команда sum, которая вводит размер файла и его контрольную сумму. Предназначена эта команда для проверки правильности передачи данных:
Порядок байтов
Несмотря на все описанные выше недостатки, иногда двоичные данные оказываются необходимы. Например, они несравненно более компактны и их гораздо быстрее декодировать, а эти факторы очень важны для компьютерных сетей. Но двоичные данные имеют серьезнейшие] проблемы с переносимостью.
По крайней мере один вопрос решен: все современные машины имеют! 8-битовые байты. Однако все объекты, большие байта, представляются на разных машинах по-разному, поэтому полагаться на какие-то определенные свойства было бы ошибкой. Короткие целые числа (обычно] 16 битов, или 2 байта) могут иметь младший байт, расположенный как по меньшему адресу (little-endian, младшеконечное расположение), чем I старший, так и по большему (big-endian, старшеконечное)1. Выбор варианта произволен, а некоторые машины вообще поддерживают обе! модели.
Итак, несмотря на то, что и старшеконечные и младшеконечные машины рассматривают память как последовательность слов, расположен-! ных в одном и том же порядке, байты внутри слова они интерпретируют! различно. На приведенной диаграмме четыре байта, начинающиеся с поя зиции 0, представляют шестнадцатеричное целое 0x11223344 для старшеконечников и 0x44332211 —для младшеконечников.
Результат будет одинаковым для большинства
Результат будет одинаковым для большинства распространенных машин:
char 1, short 2, int 4, long 4, float 4, double 8, void* 4
однако возможны и другие значения. Некоторые 64-битовые машины покажут такие значения:
char 1, short 2, int 4, long 8, float 4, double 8, void* 8
а ранние компиляторы под PC показали бы такое:
char 1, short 2, int 2, long 4, float 4, double 8, void* 2
Во времена появления PC аппаратура поддерживала несколько видов указателей. Для того чтобы справиться с такой неразберихой, были придуманы модификаторы указателей far и near, ни один из которых не входит в стандарт, но до сих пор эти ключевые слова-призраки появляются во многих компиляторах. Если ваш компилятор может менять размеры базовых типов или если вы имеете доступ к машинам, поддерживающим другие размеры, постарайтесь скомпилировать и оттестировать вашу программу при таких новых для нее условиях.
Стандартный заголовочный файл stddef. h определяет ряд типов, которые могут помочь с переносимостью. Наиболее часто используемый из них — size_t, который представляет собой тип беззнакового целого, возвращаемого оператором sizeof. Значения этого типа возвращаются функциями типа strlen и во многих функциях, включая mall ос, используются в качестве аргументов.
Наученная чужим горьким опытом, Java четко определяет размеры всех своих базовых типов: byte — 8 битов, char и short — 16, int — 32 и long — 64 бита.
Мы не будем рассматривать набор проблем, связанных с вычислениями с плавающей точкой, потому что разговор об этом достоин отдельной книги. Скажем только, что большинство современных машин поддерживают стандарт IEEE на аппаратуру для плавающей точки, и, следовательно, для них свойства арифметики с плавающей точкой определены достаточно четко.
Порядок вычислений. В С и C++ порядок вычислений операндов выражений, побочных эффектов и аргументов функций не определен. Например, в присваивании
? n = (getcharQ « 8) getchar();
второй getcha r может быть вызван первым: порядок, в котором выражение записано, не обязательно соответствует порядку, в котором оно исполняется.
значение count может быть увеличено
В выражении
? ptr[count] = name[++count];
значение count может быть увеличено как до, так и после использования его в качестве индекса pt г, а в выражении
? . printf("%c %c\n", getchar(), getchar());
первый введенный символ может быть распечатан на втором месте, а не на первом. В выражении
? printf("%f %s\n", logC-1.23), strerror(errno));
значение errno может оказаться вычисленным до вызова log.
Для некоторых выражений существуют четкие правила вычисления. По определению все побочные эффекты и вызовы функций должны быть завершены до ближайшей точки с запятой или при вызове функции. Операторы && и | | выполняются слева направо и только до тех пор, пока это требуется для определения их значения (включая побочные эффекты). В операторе ?: сначала вычисляется условие, включая возможные побочные эффекты, и только после этого вычисляется одно из двух завершаюшжс оператор выражений.
В Java порядок вычислений описан более жестко. В нем предусмотрено, что выражения, включая побочные выражения, вычисляются слева направо; правда, в одном авторитетном руководстве дан совет не писать кода, который бы "критично" зависел от этого порядка. Прислушаться к этому совету просто необходимо при создании программ, у которых есть хотя бы призрачный шанс конвертироваться в С или C++: как мы уже сказали, там нет никаких гарантий соблюдения такого же порядка. Конвертирование из одного языка в другой — экстремальный, но иногда весьма полезный тест на переносимость программы.
Наличие знака у char. В С и C++ не определено, является ли char знаковым или беззнаковым типом данных. Это может привести к проблемам при использовании комбинаций char и int, как, например, в приводимом коде, где вызывается функция getchar(), возвращающая значение типа int: Если вы напишете
?char с; /* должно было быть int */
? с = getchar();
то значение с будет в диапазоне от 0 до 255, если char — беззнаковый тип, и в диапазоне от -128 до 127, если char — знаковый тип; речь идет о практически стандартной конфигурации с 8-битовыми символами на машинах с дополнительным до двух кодом.Это имеет особый смысл, если символ должен использоваться как индекс массива или для проверки на EOF, который в stdio обычно представляется значением -1. Например, представим, что мы разработали этот код из параграфа 6.1 после исправления некоторых граничных условий в начальной версии. Сравнение s[i] == EOF никогда не будет истиной, если char — беззнаковый тип:
с EOF его значение останется
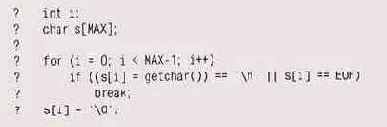
Когда getchar возвратит EOF, в s[i] будет сохранено значение 255 (OxFF, результат преобразования -1 в unsigned char). Если s[i] беззнаковое, то при сравнении с EOF его значение останется 255, и, следовательно, проверка не пройдет.
Однако, даже если char является знаковым типом, код все равно некорректен. В этом случае сравнение с EOF будет проходить нормально, но при вводе вполне допустимого значения OxFF оно будет воспринято как EOF и цикл будет прерван. Так что вне зависимости от того, знаковый или беззнаковый у вас char, хранить значение, возвращаемое getcha r, вы должны в int, и тогда проверка на конец файла будет осуществляться нормально. Вот как должен выглядеть наш цикл в переносимом виде:
В языке Java вообще нет
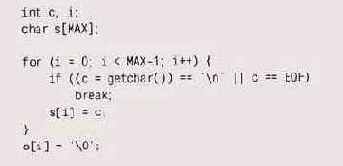
В языке Java вообще нет спецификатора unsigned; порядковые типы данных являются знаковыми, а тип char (16-битовый) — беззнаковым.
Арифметический или логический сдвиг. Сдвиг вправо знаковых величин с помощью оператора » может быть арифметическим (при сдвиге распространяется копия знакового бита) или логическим (при сдвиге освободившиеся биты заполняются нулями). И здесь Java, наученная горьким опытом С и C++, резервирует » для арифметического сдвига вправо и предоставляет отдельный оператор >» для логического сдвига вправо.
Порядок байтов. Порядок байтов внутри short, int и long не определен; байт с младшим адресом может быть как наиболее значимым, так и наименее значимым. Этот вопрос зависит от аппаратуры, и мы подробно обсудим его несколько ниже в этой главе.
Выравнивание членов структуры или класса. Расположение элементов внутри структур, классов и объединений (union) не определено, утверждается лишь, что члены располагаются в порядке объявления. Например, в структуре
может находиться на расстоянии

адрес 1 может находиться на расстоянии 2, 4 или 8 байтов от начала структуры. Некоторые (немногие) машины позволяют целым храниться на нечетных границах, но большинство требует, чтобы п-байтовые элементарные типы данных хранились на и-байтовых границах, чтобы, например, double, которые имеют, как правило, длину в 8 байтов, хранились по адресам, кратным 8. В дополнение к этому создатели компиляторов могут вносить и свои ограничения — такие как принудительное выравнивание для повышения производительности.
Никогда не рассчитывайте на то, что элементы структуры занимают смежные области памяти. Ограничения на выравнивание вызывают появление "дыр" в структурах — так, st ruct X всегда будет содержать по крайней мере один байт неиспользуемого пространства. Из-за этих дыр размер структуры может быть больше, чем сумма размеров ее членов, причем этот размер может быть разным на разных машинах. Если вы хотите зарезервировать память под структуру, всегда запрашивайте sizeof (struct X) байтов, ноне sizeof (char) + sizeof(int).
Битовые поля. Битовые поля настолько зависят от конкретных машин, что никому не следует их использовать.
Все перечисленные опасные места можно миновать, следуя нескольким правилам. Не используйте побочные эффекты нигде, кроме как в идиоматических конструкциях типа
с EOF. Всегда используйте sizeof

Не сравнивайте char с EOF. Всегда используйте sizeof для вычисления размера типов и объектов. Никогда не сдвигайте вправо знаковые значения. Убедитесь, что тип данных достаточно велик для диапазона значений, которые вы собираетесь в нем хранить.
Попробуйте несколько компиляторов. Иногда вам может показаться, что вы решили все проблемы с переносимостью, однако компиляторы в состоянии увидеть проблемы, который не вы заметили, и вообще, раз-, ные компиляторы воспринимают вашу программу по-разному, и этим; можно воспользоваться. Включите все предупреждения компилятора. Попробуйте использовать разные компиляторы на одной машине и на разных машинах. Попытайтесь компилировать вашу С-программу на компиляторе C++.
Поскольку язык, воспринимаемый различными компиляторами, может несколько отличаться от стандарта, тот факт, что ваша программа компилируется одним компилятором, не дает гарантии даже того, чтс она корректна синтаксически. А вот если несколько компиляторов принимают ваш код, значит, все не так плохо. Мы компилировали каждув программу, приведенную в книге, на трех компиляторах С для трех различных операционных систем (Unix, Plan 9, Windows) и на паре компиляторов C++. При таком подходе были найдены десятки ошибок переносимости — никакое самое пристальное изучение программ чeлoвeкoм не смогло бы найти их все. Исправлялись же все ошибки тривиально.
Естественно, сами компиляторы тоже вызывают проблемы с переносимостью из-за разного толкования не описанных в стандарте случаев. Однако наш подход — писать программы, избегая применения деталей, которые могут варьироваться, позволяет надеяться на создание программ, работающих вне зависимости от внешних условий.
Даже из этого сравнительно простого

Даже из этого сравнительно простого примера видно, что заголовочные файлы и программы, структурированные подобным образом, получаются довольно запутанными и сопровождать их достаточно сложно. Возможно, проще использовать отдельный заголовочный файл для каждого компилятора или среды. При этом придется сопровождать множество отдельных файлов, но каждый из них будет предназначен только для использования в конкретной конфигурации, что уменьшит вероятность появления ошибок вроде включения функции st rdup в среду, строго поддерживающую стандарт ANSI С.
Заголовочные файлы также иногда "засоряют" пространство имен, определяя функции с именами, уже использующимися в программе. Например, наша функция оповещения об ошибках wep rintf изначально называлась wp rintf, однако мы выяснили, что в некоторых средах функция с таким именем определена в stdio. h (можно сказать, что сделано это в преддверии нового стандарта С). Для того чтобы скомпилировать программу в этих средах и защитить себя в будущем, нам пришлось изменить название своей функции. Если бы проблема состояла в некорректном компиляторе, а не в ожидаемом изменении спецификации, как в нашем случае, то ее можно было бы решить, переопределяя имя при подключении заголовочного файла:

Этот фрагмент изменяет все появления wprintf в заголовочном файле на stdio_wp rintf, так что теперь они не повлияют на нашу версию. Теперь мы можем использовать нашу wprintf, не изменив ее имени, правда, при этом неизбежно появится некая путаница, а также риск, что подключенная библиотека будет вызывать нашу wprintf, подра-
зумевая обращение к своей версии. Для одной функции проблемы, может, и невелики, но уже для нескольких лучше придумать более радикальное решение. Всегда комментируйте назначение конструкции; без крайней необходимости не ухудшайте ее добавлением условной компиляции. Если в некоторых средах определена wprintf, то стоит считать, что она определена во всех; тогда единственный разумный выход — переименовать ее, избавившись при этом от выражения tfifdef. Нередко проще не превозмогать трудность, а подстраиваться под нее; да это и безопаснее, вот почему мы решили переименовать свою функцию в weprintf.
Даже если вы следуете всем правилам и неясностей со средой не возникает, все равно вполне возможно появление ошибок. Так, можно ошибиться, предположив, что какая-нибудь ваша излюбленная возможность одинакова во всех системах. К примеру, ANSI С определяет шесть сигналов, которые можно поймать с помощью signal, в стандарте POSIX их определено 19, а большинство"систем Unix поддерживает 32 и более. Если вы хотите использовать сигнал, отличный от описанного в ANSI С, вам придется выбирать между функциональностью и переносимостью, так что сами решайте *ITO для вас важнее.
Существует болыпсте количество других стандартов, не являющихся частью определения языка: среди них можно назвать интерфейсы операционных систем и сетей, графические интерфейсы и тому подобные вещи. Некоторые стандарты распространяются на несколько систем — например POSIX; другие определены исключительно для одной системы, например различные API Microsoft Windows. Здесь можно еще раз повторить наши главные советы: ваша программа станет более переносимой, если вы выберете самые распространенные и устоявшиеся стандарты и будете пользоваться самыми важными и общепринятыми их свойствами. <>
Защитный стиль приемлем, если он
Защитный стиль приемлем, если он применяется время от времени,; а не всегда. Возникает резонный вопрос: а для скольких еще функций из stdlib. h придется писать аналогичный код? В частности, если вы собираетесь использовать mall ос и real loc, то явно потребуется еще и free. А что, если тип unsigned int нетождественен size_t — правильному типу аргумента для malloc и realloc? Более того, откуда мы знаем, что STOC_HEADERS и _LIBC определены, и определены корректно? Можем ли мы быть уверенными в том, что не существует другого имени, которое потребует замены для другой среды? Любой условный код вроде этого неполон, а значит — непереносим, поскольку рано или поздно встретится система, не удовлетворяющая его условию, и тогда придется редактировать #ifdef. Если нам удастся решить задачу без помощи условной компиляции, мы избавимся и от проблем, связанных с дальнейшим поддержанием этого кода.
Итак, проблема, которая решается в рассмотренном примере, существует в реальности. Так как же нам решить ее раз и навсегда? На самом деле нам просто надо предположить, что стандартные заголовочные файлы присутствуют во всех системах всегда; если одного из них нет, то это уже не наши проблемы. Но мы можем решить и их; для данного случая достаточно вместе с программой поставить и заголовочный файл, который определяет malloc, realloc и free в точности так, как этого требует стандарт ANSI С. Такой файл всегда может быть включен полностью вместо "заплаток", и мы будем уверены, что нужный интерфейс обеспечен.
Избегайте условной компиляции. Условной компиляцией с помощью ttifdef и подобных ей директив препроцессора трудно управлять, поскольку информация оказывается рассеянной по всему коду:
В этом фрагменте, вообще говоря,
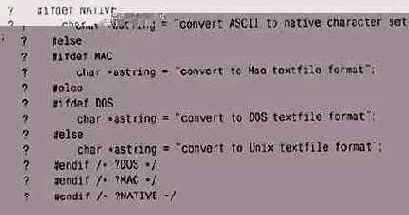
В этом фрагменте, вообще говоря, лучше было бы использовать tfelif после каждого определения — тогда бы не было такого ненужного скопления tfendif в конце. Однако главная проблема вовсе не в этом, а в том, что, несмотря на все старания, код плохо переносим, потому что он ведет себя по-разному в разных системах, а для работы в каждой новой системе должен быть дополнен новым Sifdef. Одна-единственная строка с унифицированным текстом (но на самом деле столь же информативным) была бы гораздо удобнее, проще и переносимее:
char *astring = "convert to local text format";
Для этой строки никаких условий не нужно, она будет выглядеть одинаково во всех системах.
Смешивание управляющей логики времени компиляции (определяемой выражениями «if def) и времени исполнения приводит к еще более трудно воспринимаемому коду:
Даже будучи явно безопасной, условная
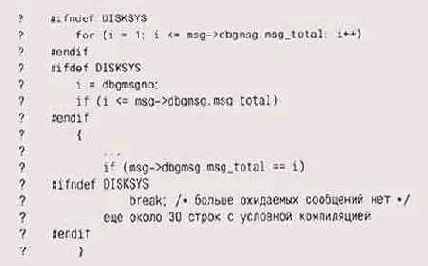
Даже будучи явно безопасной, условная компиляция может быть заменена более простым кодом. Например, tfifdef часто используют для управления отладочным кодом:
? ftifdef DEBUG
? printf(...);
? tfendif
однако обычное выражение if с константой в условии может делать то же самое:
Если DEBUG есть ноль, то

Если DEBUG есть ноль, то большинство компиляторов не сгенерируют для приведенного фрагмента никакого кода, но при этом они еще и проверят синтаксис. Секция с #if def, наоборот, может содержать синтаксические ошибки, которые сорвут компиляцию, как только соответствующее условие #if def окажется выполнено.
Иногда условия компиляции содержат большие блоки кода:
tfifdef notdef /* неопределенный символ */ ttendif
или
#if О
tfendif
В таком случае этот код лучше вынести в отдельные файлы, которые будут подключаться при компиляции при соблюдении определенных условий. К этой теме мы еще вернемся в следующем разделе.
Начиная адаптировать программу к новой среде, не делайте копии всей программы, а перерабатывайте исходный код. Скорее всего, вам придется вносить изменения в основное тело программы, и при редактировании копии вы через какое-то время получили бы новую, отличающуюся от исходной версию. Изо всех сил стремитесь к тому, чтобы у вас существовала единственная версия программы; при необходимости подстроиться под конкретную систему старайтесь вносить изменения таким образом, чтобы они работали во всех системах. Измените внутренние интерфейсы, если надо, но не нарушайте целостности кода; не пытайтесь решить проблему с помощью #if def. При таком подходе каждое изменение сделает вашу программу все более переносимой, а не более специализированной. Сужайте пересечение, а не расширяйте объединение.
Мы уже привели много доводов против использования условной компиляции, но не упоминали еще о главной проблеме: ее практически невозможно оттестировать. Каждое выражение tfif def разделяет всю программу на две по отдельности компилируемые программы, и определить, все ли возможные варианты программ были скомпилированы и проверены, очень сложно. Если в один блок tfifdef было внесено изменение, то может статься, что изменить надо и другие блоки, но проверить эти изменения можно будет только в той среде, которая вызовет эти tfifdef к исполнению. Точно так же, если мы добавляем блок #if def, то трудно изолировать это изменение, то есть определить, какие еще условия должны быть учтены и в каких еще местах должен быть изменен код. Наконец, если некий блок кода должен быть опущен в соответствии с условием, то компилятор его просто не видит, и проверить этот блок можно только в соответствующей конфигурации. Вот небольшой пример подобной проблемы — программа компилируется, если _МАС определено, и отказывается это делать в противном случае:
мы предпочитаем использовать только те

Итак, мы предпочитаем использовать только те возможности, которые присутствуют во всех средах, где будет исполняться программа. Мы всегда можем скомпилировать и протестировать весь код. Если что-то вызывает проблемы с переносимостью, мы переписываем этот кусок, а не добавляем условно компилируемый код; таким образом, переносимость все время улучшается.
Некоторые большие системы распространяются с конфигурационными скриптами, которые помогают приспособить код к локальной среде. Во время компиляции скрипт проверяет возможности среды: расположение заголовочных файлов и библиотек, порядок байтов внутри слов, размер типов, уже известные неверные реализации функций (таких на удивление много) и т. п. — и генерирует параметры настройки или make-файлы (makefile), которые описывают нужные настройки для данной ситуации. Эти скрипты могут быть большими и сложными, они являются важной частью дистрибутивного пакета и требуют постоянной поддержки. Иногда такие сложные способы оказываются полезны, но все же, чем переносимее будет ваш код и чем меньше #if def будет в нем использова-' но, тем проще и безопаснее будет происходить его настройка и установка.
При каких обстоятельствах компилятор проверяет

При каких обстоятельствах компилятор проверяет синтаксис? Когда он генерирует код?
Если у вас есть доступ к разным компиляторам, поэкспериментируйте с ними и сравните результаты. <
Для того чтобы увидеть порядок
Для того чтобы увидеть порядок байтов в действии, запустите следующую программу:
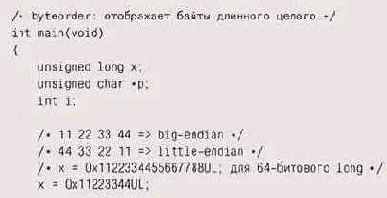
битовом старшеконечнике на экран будет

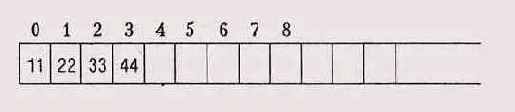
На 32- битовом старшеконечнике на экран будет выведено
11 22 33 44
на младшеконечнике —
44 33 22 11
а на PDP-11 (16-битовая машина, все еще встречающаяся во встроенных системах) результатом будет
22 11 44 33
На машинах с 64-битовым типом long мы можем рассмотреть константу большей длины и увидеть те же результаты.
Наша программа выглядит довольно глупо, но если нам надо послать целое число через побайтовый интерфейс, например по сети, то надо решить, какой байт посылать первым, а какой вторым, и в этом выборе суть проблемы со старше- и младшеконечниками. Другими словами, наша программа неявнр выполняет то, что выражение
fwrite(&x, sizeof(x), 1, stdout);
делает явным образом. Небезопасно писать (отправлять) int (или short, или long) на одном компьютере и читать это число как int на другом.
Например, если компьютер-передатчик пишет с помощью
unsigned short x;
fwrite(&x, sizeof(x), 1, stdout);
а компьютер-приемник производит чтение так:
unsigned short x;
fread(&x, sizeof(x), 1, stdin);
то, если эти компьютеры имеют разный порядок байтов, значение х будет воспроизведено неправильно. Например, если отправлено было число 0x1000, то прочитано оно будет как 0x0010.
Эта проблема часто решается посредством условной компиляции и перестановки байтов, то есть примерно так:
При пересылке большого количества двух-

При пересылке большого количества двух- и четырехбайтовых целых такой подход получается слишком громоздким. На практике получает- ; ся, что байты при пересылке не один раз подвергаются перестановке.
Если ситуация выглядит невесело для short, то для более длинных типов она еще хуже — для них существует больше способов перепутать байты. А если к этому добавить еще всяческие преобразования между членами структур, ограничения на выравнивание и абсолютно таинственный порядок байтов в старых машинах, то проблема покажется 4 просто неразрешимой.
Используйте при обмене данными фиксированный порядок байтов.
Решение проблемы все же существует. Записывайте байты в каноническом порядке, используя переносимый код:
и считывайте их обратно побайтово,
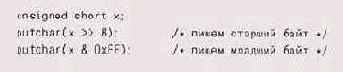
и считывайте их обратно побайтово, собирая первоначальные значения
в определенной последовательности, побайтово, без

Этот подход можно перенести и на структуры: записывайте значе-'' ния членов структур в определенной последовательности, побайтово, без выравнивания. Неважно, какой порядок байтов вы изберете, — подойдет любой, лишь бы передатчик и приемник согласовали порядок байтов в передаче и количество байтов в каждом объекте. В следующей главе мы покажем несколько инструментов для упаковки и распаковки данных.
Побайтовая обработка может показаться довольно дорогим удовольствием, но в сравнении с вводом-выводом, при котором необходима упаковка и распаковка данных, потери времени окажутся незначительными. Представьте себе систему X Window, в которой клиент пишет данные с тем порядком байтов, что используется у него на машине, а сервер должен распаковывать все, что клиент посылает. На клиентском конце достигнута экономия в несколько инструкций, но сервер становится больше и сложнее, поскольку ему приходится обрабатывать одновременно данные с разными порядками байтов: ведь клиенты вполне могут иметь различные типы машин. В общем, сложностей куда больше. Кроме того, не забывайте, что это графическая оболочка, где расходы на распаковку байтов будут с лихвой перекрыты выполнением той графической операции, которую они содержат.
Система X Window воспринимает данные от клиента с любым порядком байтов: считается, что это забота сервера. А система Plan 9, наоборот, сама задает порядок байтов для отправки сообщений файл-серверу (или графическому серверу), а данные запаковываются и распаковываются неким универсальным кодом вроде приведенного выше. На практике определить временные затраты во время исполнения оказывается практически невозможно; можно только сказать, что на фоне ввода-вывода упаковка данных оказывается малозаметной.
Java — язык более высокого уровня, чем С и C++, в нем порядок байтов скрыт совсем. Библиотеки представляют интерфейс Serializable, который определяет, как элементы данных пакуются для передачи.
Однако, если вы пишете на С или C++, всю работу придется выполнять самостоятельно.
что можно сказать про побайтовую
Главное, что можно сказать про побайтовую обработку: она решает имеющуюся проблему для всех машин с 8-битовыми байтами, причем решает без участия flifdef. Мы еще вернемся к этой теме в следующей главе.
Итак, лучшим решением нередко оказывается преобразование информации в текстовый формат, который (не считая проблемы CRLF) является абсолютно переносимым: не существует никаких неопределенностей с его представлением. Однако и текстовый формат не является панацеей. Время и размер для некоторых программ могут быть критичны, кроме того, часть данных, особенно числа с плавающей точкой, могут потерять точность при округлениях в процессе передачи через printf и scanf. Если вам надо передавать числа с плавающей точкой, особо заботясь о точности, убедитесь, что у вас есть хорошая библиотека форматированного ввода-вывода; такие библиотеки существуют, просто ее может не оказаться конкретно в вашей системе. Особенно сложно представлять числа с плавающей точкой для переноса их в двоичном формате, но при должном внимании текст может эту проблему решить.
Существует один тонкий момент, связанный с использованием стан-| дартных функций для обработки двоичных файлов, — эти файлы необходимо открывать в двоичном режиме:
в большинстве систем Unix это

Если ' b' опущено, то в большинстве систем Unix это ни на что не повлиЯ яет, но в системах Windows первый встретившийся во вводе байт 1 Control-Z (восьмеричный 032, шестнадцатеричный 1А) прервет чтение! (такое происходило у нас с программой st rings из главы 5). В то же вре- j мя при использовании двоичного режима для чтения текстовых файлов; вам придется вставлять символы \ r во ввод и убирать их из вывода. <
После передачи контрольная сумма не

После передачи контрольная сумма не изменилась, так что с хорошей вероятностью можно считать, что передача прошла успешно.
Система разрасталась, появлялись новые версии, и в какой-то момент кто-то решил, что алгоритм вычисления контрольной суммы не идеален, и sum была изменена с использованием лучшего алгоритма. Кто-то еще пришел к тому же выводу и тоже изменил sum, реализовав другой, столь же хороший алгоритм, и т. д. В результате сейчас имеется несколько версий sum, каждая из которых выдает свой вариант ответа. Мы поставили ссперимент, скопировав некий файл на другие машины, чтобы выяснить, жие же результаты покажет sum в каждом конкретном случае:
в передаче или просто мы

Непонятно, произошел сбой в передаче или просто мы столкнулися разными версиями sum. Может быть и то, и другое.
Таким образом, sum являет собой яркий пример препятствия на пути! переносимости: программа, призванная помогать в копировании фай-] зв с одной машины на другую, имеет несколько несовместимых версий,! го делает ее абсолютно непригодной для использования.
Для выполнения изначально поставленной задачи первая версия sum] юлнелодходила: алгоритм, заложенный в ней, был не самым эффектив-1 JM, но приемлемым. Ее "улучшение", может, и сделало собственно ко-анду лучше, но зато использовать ее по назначению стало нельзя. И деля 'т, надо сказать, не в том, что получилось несколько разных по существу! зманд, а в том, что все эти команды имеют одно и то же имя. Как видите! юблема несовместимости версий может оказаться весьма серьезной.
Поддерживайте совместимость с существующими программами и данными. Когда выпускается новая версия программы, например текстового редактора, то она, как правило, умеет читать файлы, созданньЯ эедыдущей версией. При этом мы ожидаем, что из-за добавления новых возможностей формат должен измениться. Но зачастую новые версии оказываются не в состоянии обеспечить способ записи в предыдущем формате. Пользователи новых версий, даже если они не обращаются к добавленным возможностям, не могут применять свои файлы совместно с пользователями более старой версии, таким образом, обновлять программы приходится сразу всем. Независимо от того, чем определяются такие решения — технической необходимостью или маркетинговой политикой, — о таких случаях можно только сожалеть.
Совместимостью сверху вниз называется возможность программы соответствовать спецификациям своих более ранних версий. Если вы собираетесь изменить свою программу, убедитесь, что при этом вы не создадите противоречий со старыми версиями и связанными с ними данными. Тщательно документируйте изменения и продумайте способ восстановить первоначальные возможности. И главное, задумайтесь над тем, перевесят ли достоинства предлагаемых вами усовершенствований потери от непереносимости, которые при этом возникнут. <
как ваш компилятор обрабатывает код,
Выясните, как ваш компилятор обрабатывает код, содержащийся внутри условного блока типа
Напишите программу, которая бы удаляла
Напишите программу, которая бы удаляла из файла случайно образовавшиеся возвраты каретки. После этого напишите еще одну, которая бы добавляла их в файл, заменяя символы перевода строки комбинацией возврата каретки и перевода строки. Как вы будете тестировать эти программы? <
Заголовочные файлы и библиотеки
Заголовочные файлы и библиотеки предоставляют возможности, расширяющие базовый язык. Например, ввод и вывод осуществляются с помощью библиотек stdio в С, lost ream в C + + и Java, io в Java. Строго говоря, эти элементы не являются частью языка, но они определен! вместе с языком и представляют собой составную часть любой среды, поддерживающей этот язык. Однако, поскольку библиотеки покрывают широкий спектр возможностей и нередко имеют дело со специфическими вопросами устройства операционных систем, в их использовании может крыться причина плохой переносимости программы.
Используйте стандартные библиотеки. Здесь, как и при обсуждении самого языка, применимо то же самое общее правило: придерживайтесь стандарта, отдавая предпочтение старым, устоявшимся компонентам. В С определена стандартная библиотека функций ввода-вывода, операций со строками, проверок символов, выделения памяти под данные и ряда других задач. Если вы ограничите взаимодействие своей программы с операционной системой использованием этих функций, с хорошей долей уверенности можно считать, что программа будет вести себя одинаково при переходе от одной операционной системы к другой. Однако и здесь надо соблюдать осторожность: существуют различные реализации библиотек, и некоторые из них имеют отклонения от стандарта.
В ANSI С не определена функция копирования строк st rdup, хотя она имеется в большинстве сред программирования — даже в тех, что декларируют строгую приверженность стандарту. Может показаться заманчивым использовать данную функцию, но делать этого не следует: компилятор не предупредит вас, что функция не стандартная, а в дальнейшем программу будет не перенести в среду, этой функции не имеющую. Проблемы подобного рода — основной источник головной боли при использовании библиотек, и единственное решение — придерживаться стандарта и тестировать свою программу на возможно большем количестве конфигураций.
Заголовочные файлы и описания пакетов описывают интерфейс со стандартными функциями. Один из недостатков многих заголовочных файлов состоит в том, что в них приводятся описания сразу для нескольких языков. Нередко можно встретить один файл вроде stdiо. h с описаниями одновременно для старого (до стандарта ANSI) С, ANSI С и даже C++ компиляторов. Такой файл получается очень громоздким — в нем много директив условной компиляции вроде #if и ffif def. Язык препроцессора не слишком гибок, поэтому такие файлы получаются довольно сложными для восприятия; иногда в них даже содержатся ошибки.
Ниже приведен фрагмент заголовочного файла одной из систем, причем он еще гораздо лучше многих, по крайней мере нормально отформатирован:
к которому надо стремиться, поскольку
Переносимый код — это идеал, к которому надо стремиться, поскольку только он способен сэкономить вам время при переносе программы из системы в систему или при изменении текущего окружения. Однако переносимость достается не бесплатно — вам придется быть особенно внимательными при написании кода, а также представлять себе детали всех потенциально пригодных систем.
Мы рассмотрели два подхода к обеспечению переносимости — объединение и пересечение. Объединение предусматривает создание ; версий, которые работают в каждой конкретной среде; акцент при этом делается на механизмы вроде условной компиляции. Недостатков у этого подхода много: требуется писать больше кода, и нередко этот код получается весьма сложным; трудно изменять версии, очень трудно тестировать.
Пересечение предусматривает написание возможно большей части кода так, чтобы он работал без каких-либо изменений или условий в любой системе. Обработка системных различий, от которых все равно никуда не денешься, должна быть вынесена в отдельные файлы, которые будут играть роль интерфейса между программой и конкретной системой. И у этого подхода есть свои недостатки, главным из которых является потенциальное ухудшение производительности и даже возможностей, но в общем и целом все недостатки окупаются открывающимися преимуществами.
